
复盘-非典型数据团队从0到1

在此做个简单的复盘,给大家讲一个数据团队从0到1的故事。说是非典型,因为有一个好消息和一个坏消息,坏消息是数据团队与总部不在同一个城市,得不到总部的资源。好消息是我们有易鲸捷这个出身于惠普的分布式数据库团队做支持。 温馨提示:对大数据技术及产品不感兴趣的朋友可以直接拉到文末看心得总结。
0. 一个人Know Nothing
我就像是进入了一个密室,外面人都说这里埋着宝藏,可是我一头闯进来后却一片漆黑完全找不到方向。Google,看书,沿着一条条线索查询,如同盲人摸象,一会摸到了鼻子,一会摸到了尾巴,可是完全不知道整体是怎样,脑子里只有一堆堆的困惑,交织在一起,理不出头绪。渐渐,随着一个个问题的解答,像是拉开了这个密室的一个个窗帘,光渐渐地透进来,终于对整体的轮廓有了了解,可是越是了解,越是恐慌,太多的东西要学,这不是一个人能完成的任务。
历经波折,在易鲸捷公司的协助下,在这一阶段我完成了公司大数据基础设施的组建。包括硬件、网络、基于CDH 的大数据平台(包含HDFS,Yarn,Hive,HBase,Zookeeper,Oozie,Hue等组件)和EsgynDB。
在此感谢 易鲸捷公司并将其产品推荐给大家,其产品商业版本叫EsgynDB,开源版本叫Trafodion,为Apache孵化项目,Github项目链接 https://github.com/apache/incubator-trafodion。
踩过的坑1
被建议用Openresty自己写日志收集服务,花了很长时间研究后发现根本没必要,Flume和Kafka已经非常成熟而且有众多应用。
踩坑体会:在初期,非核心组件尽量使用成熟开源工具,降低成本。
踩过的坑2
被建议使用d3js来完成数据可视化,研究后发现d3js使用门槛比较高,百度的echarts库简单易用,效果也足够好。
踩坑体会:技术选型不必一味追求高大上,满足需求,简单易用才是合适。
1. 初创团队-数据接入
根据之前的摸索,我将数据架构分为了数据接入层、数据仓库层和数据应用层,并以此架构开始搭建数据团队。
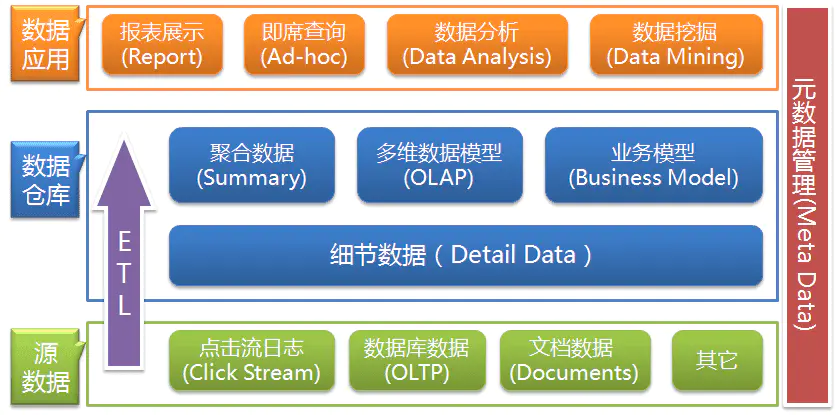
借用一张非常好的架构图,源自 数据仓库的基本架构(http://www.woshipm.com/pd/676.html)
第一步先收集数据。
技术端,因为数据收集服务的技术选型为Flume和Kafka,所以需要寻找Java系的开发人员。团队中第一个人是最不好招的,更何况团队与总公司不在同一个城市。在这个“冷启动”的阶段,我的策略是不求招到熟练使用Flume和Kafka的研发,转而关注有Java背景,学习能力和工作意愿强,经验在1-3年间的Java开发工程师。谢天谢地,我在不长的时间内招到了2位Java web开发工程师。开始了组建团队的第一步。
产品端,我开始调研数据源,主要数据来源有业务数据,用户行为数据和第三方数据。相对于一般不会出问题的业务数据和没有那么容易拿到的第三方数据,用户行为数据最着急,因为晚收集一天就少一天数据,所以我先从用户行为数据下手,开始设计移动端的埋点方案。这里感谢神策数据和GrowingIO的无私分享,两家公司在知乎等平台发表了大量高质量文章介绍埋点方案,帮助我理清了埋点原理和落地方案。
埋点方案交给移动端研发团队实现的同时,Java研发同学也在设置Flume,创建Kafka的Topic,编写Kafka Consumer。保证数据收集服务快速上线,尽可能少丢失用户行为数据。
踩过的坑
这段时间我犯了一个原则性错误,导致埋点方案臃肿而不合理。公司这时候还没建立起完整的运营团队,所以我在没有运营团队的需求之前就开始设计埋点,导致埋点无法满足需求,后期经常遇到需要的源数据没有收集,而很多埋点又闲置的尴尬,以至后来不得不重构了整个埋点方案。
踩坑体会:需求,需求,需求,不讲需求和场景的产品经理就是耍流氓。
2. 渐入佳境-数据仓库
有了数据,接下来要存储分析,最主要的任务就是构建数据仓库。常见的大数据构架下,负责数据存储的是HDFS,负责数据分析的Hive,但因为EsgynDB的存在,我们的架构简单了很多,Kafka的数据直接写入EsgynDB,然后在EsgynDB中使用ANSI SQL做ETL,建立数据仓库和离线分析,这就是SQL On Hadoop的优势,标准SQL被转为分布式计算,免去写MR和HQL这种门槛相对高的工作。

来自灵魂的Freestyle手绘画风架构图对比
这样的构架使我们在只有一个大数据工程师的情况就建立了数据仓库层,大大节省了人力成本,现在的大数据工程师的平均薪酬即使在互联网研发这个高收入人群中也算高的,面试大数据工程师的时候我经常在心里吐槽,大哥,我问的问题你都答不上来,可是你期望的税后工资比我的税前工资还高你知道么?
同时,在这一阶段,数据接入层也将业务数据库导入数据仓库,T+1, Kettle从业务数据库备库中将数据导入数仓。这样既保证不影响业务数据库,也可以相对保持数据的一致性。
至此,数据层基本搭建完毕,用户行为数据和业务数据源源不断的经过ETL流入数据仓库,数仓中的脚本们经过Oozie的调度,最终将结果汇总到以业务主题分类的结果表中。
踩过的坑1
数据清洗,这真的是见神杀神,遇佛杀佛的大坑,数据源的问题千奇百怪,没有遇不到,只有想不到。
踩坑体会:Garbage In Garbage Out
踩过的坑2
前期数据量少,直接在宽表中进行数据分析,但数据量大起来就会发现,没有建模分析真的慢。稍作优化,性能就有成倍的提高。
踩坑体会:即使到了大数据时代,很多经典的数仓理论依然没有过时,比如星型模型,大数据不是数据仓库的替代。大数据大大促进了数据仓库的发展,使数据仓库可以更大量,更快地处理类型更丰富的数据。
3. 初具雏形-数据应用
数据层基本搭建完毕,但要让数据真的被使用起来,应用层是必不可少的。初创团队对高大上的数据应用不做奢望,先把基本的报表系统做好。
报表系统提供了三种服务,数据看板(Dashboard),数据大屏和数据简报。
- 数据看板,其实可以用BDP或是微软PowerBI这种敏捷BI工具来代替,但想用好敏捷BI工具,做到数据民主化,全员数据思维和分析技能是必不可少的,要做到这一点还有很长的路,所以此阶段还是选择了以传统的固定Dashboard方式来展现。数据产品经理在此主要的工作是设计指标体系和产品原型,我的另外一篇文章-怎样做一个BI方向的数据产品经理对此做了简单介绍,欢迎大家参考。
- 数据大屏用于对外展示,BlingBling的,客户看了倍儿高兴,推荐阿里的DataV服务组建自己的数据大屏,据说阿里自己的双十一大屏就是基于DataV。但不得不吐槽,DataV不是很好用,有很多Bug,组件样式少,加载缓慢,定价模式不合理,但市面上没有其他更好的,也只能凑合用了。
- 邮件发送Excel数据简报,与数据看板互为补充,而且对于一次性需求,邮件Excel报表可以更快速的回复需求。
另外要提一句报表系统中的数据监控,数据产品经理在统计的时候经常会遇到一些莫名其妙的结果,这时候就需要到库里查哪里出了问题,非常费时费力,不如把每天的上报情况用邮件自动发送给相关人员,出了问题可以在第一时间发现。
终于,非典型数据团队初具雏形,应用层包含1位产品,1位前端开发和1位后台开发,数据层包含1位数据产品,1位大数据开发。功能上对公司内部提供数据报表支持,满足运营,市场,产品和管理层的数据需求。
踩过的坑1
关键岗位单点,比如大数据开发工程师,这是团队的核心职位之一,遭遇人员离职后直接导致团队功能失效,特别是初创团队遭遇还在试用期的核心成员提前不到一周通知的离职,惨不忍睹。
踩坑体会:关键岗位一定要有备岗,考虑成本的话可以是功能相近的两个岗位互为备岗。
踩过的坑2
缺乏资深队友,前期为了节省成本,搭建团队多考虑1-3年相关工作经验的同学,好处是年纪轻,家庭负担小,学习意愿和工作意愿强,团队氛围活跃,但是弊端也很明显,缺乏经验,稳定性低。
踩坑体会:初期快速架搭完成基本人员构架后,要开始引入3年以上工作经验的资深队友,形成高低搭配的人才梯队。
Ending
万事开头难,当然遇到的困难远不止这些,资源匮乏四个字在0到1的过程中贯穿始终,事情应该是怎样在绝大多数情况下只是美好的想象,而现实是怎样用好手里的资源尽可能的接近这个想象。看清目标,认清现实和保持信心是初创团队最重要的三项能力,而这三项能力的综合表现是,能够认清当下最需解决的问题并解决问题。
是的,这只是一个0到1的团队,完成的事情还非常少,后面有1-99都没有开始做,所以请各路大神不要吐槽。写下这篇我们的故事,一是给初创团队的朋友们提供参考,二是给我们自己做一个复盘,反思一路上的成败得失。
最后感谢陪伴一路走过来的队友们,“成年人的生活里没有容易二字”,共勉!
https://www.jianshu.com/p/a447652bcebb
作者:宫胖子想瘦
链接:https://www.jianshu.com/p/a447652bcebb
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
