
实时计算——聊一聊我所经历的计算框架
实时计算
上篇文章大致介绍了离线计算MapReduce和Spark,但是无法满足对实时性要求较高的业务,下面我们来了解一下实时计算。
离线和批量、实时和流式
在聊实时计算之前,先说一下我对离线和批量、实时和流式的一些看法。
我们首先来简单看一下计算任务的大致流程:
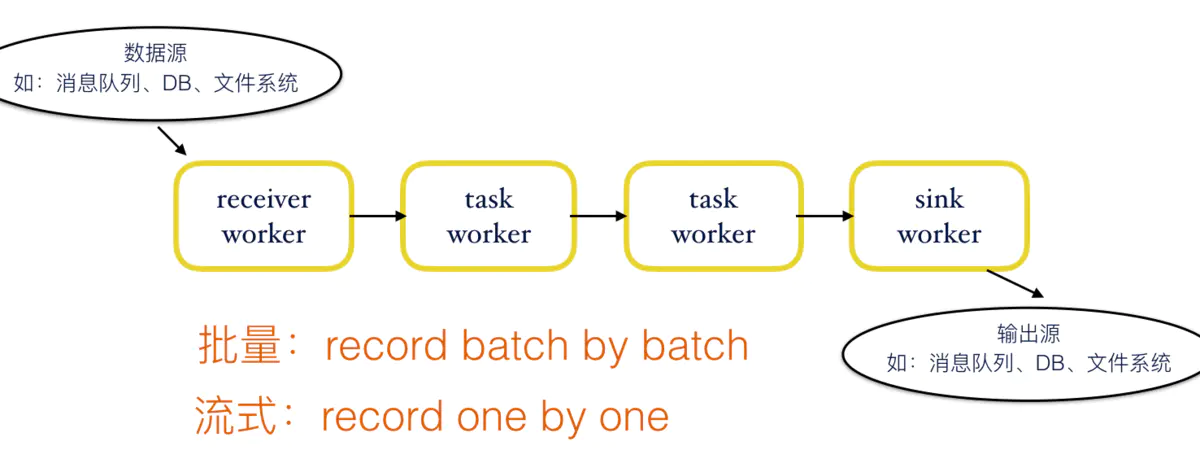
首先先说下批量计算和流式计算:
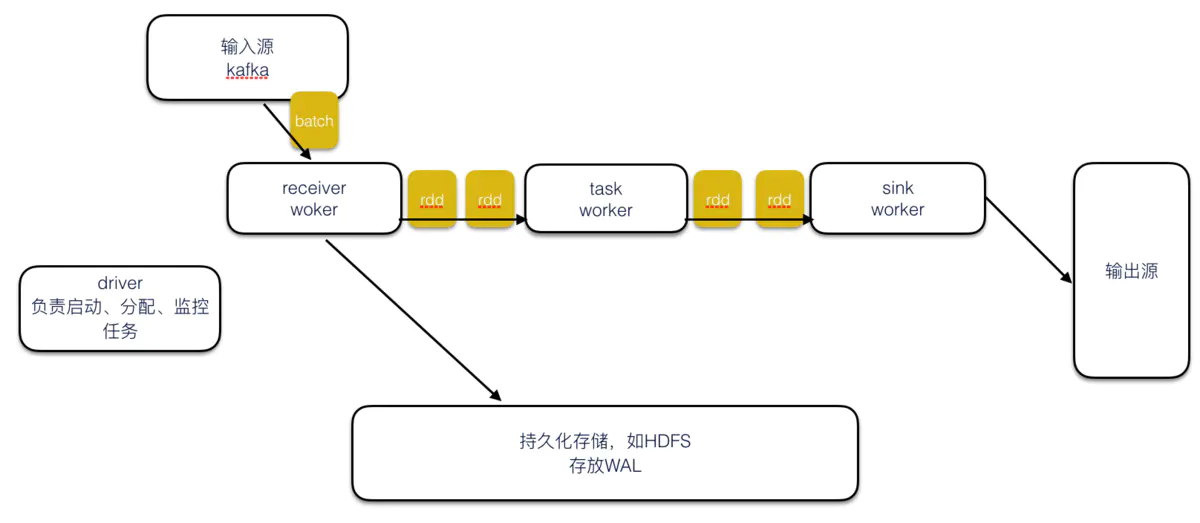
图中显示了一个计算的基本流程,receiver处负责从数据源接收数据,并发送给下游的task,数据由task处理后由sink端输出。
以图为例,批量和流式处理数据粒度不一样,批量每次处理一定大小的数据块(输入一般采用文件系统),一个task处理完一个数据块之后,才将处理好的中间数据发送给下游。流式计算则是以record为单位,task在处理完一条记录之后,立马发送给下游。
假如我们是对一些固定大小的数据做统计,那么采用批量和流式效果基本相同,但是流式有一个好处就是可以实时得到计算中的结果,这对某些应用很有帮助,比如每1分钟统计一下请求server的request次数。
那问题来了,既然流式系统也可以做批量系统的事情,而且还提供了更多的功能,那为什么还需要批量系统呢?因为早期的流式系统并不成熟,存在如下问题:
1.流式系统的吞吐不如批量系统
2.流式系统无法提供精准的计算
后面的介绍Storm、Spark streaming、Flink主要根据这两点来进行介绍。
批量和流式的区别:
1.数据处理单位:
批量计算按数据块来处理数据,每一个task接收一定大小的数据块,比如MR,map任务在处理完一个完整的数据块后(比如128M),然后将中间数据发送给reduce任务。
流式计算的上游算子处理完一条数据后,会立马发送给下游算子,所以一条数据从进入流式系统到输出结果的时间间隔较短(当然有的流式系统为了保证吞吐,也会对数据做buffer)。
这样的结果就是:批量计算往往得等任务全部跑完之后才能得到结果,而流式计算则可以实时获取最新的计算结果。
2.数据源:
批量计算通常处理的是有限数据(bound data),数据源一般采用文件系统,而流式计算通常处理无限数据(unbound data),一般采用消息队列作为数据源。
3.任务类型:
批量计算中的每个任务都是短任务,任务在处理完其负责的数据后关闭,而流式计算往往是长任务,每个work一直运行,持续接受数据源传过来的数据。
离线=批量?实时=流式?
习惯上我们认为离线和批量等价;实时和流式等价,但其实这种观点并不完全正确。
假设一种情况:当我们拥有一个非常强大的硬件系统,可以毫秒级的处理Gb级别的数据,那么批量计算也可以毫秒级得到统计结果(当然这种情况非常极端,目前不可能),那我们还能说它是离线计算吗?
所以说离线和实时应该指的是:数据处理的延迟;批量和流式指的是:数据处理的方式。两者并没有必然的关系。事实上Spark streaming就是采用小批量(batch)的方式来实现实时计算。
可以参考下面链接:https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101。作者是Google实时计算的负责人,里面阐述了他对批量和实时的理解,并且作者认为批量计算只是流式计算的子集,一个设计良好的流式系统完全可以替代批量系统。本人也从中受到了很多启发。
介绍完这些概念后,下面我们就来简单看看目前流行的实时计算框架的实现和区别。
Storm
Storm做为最早的一个实时计算框架,早期应用于各大互联网公司,这里我们依然使用work count举例:
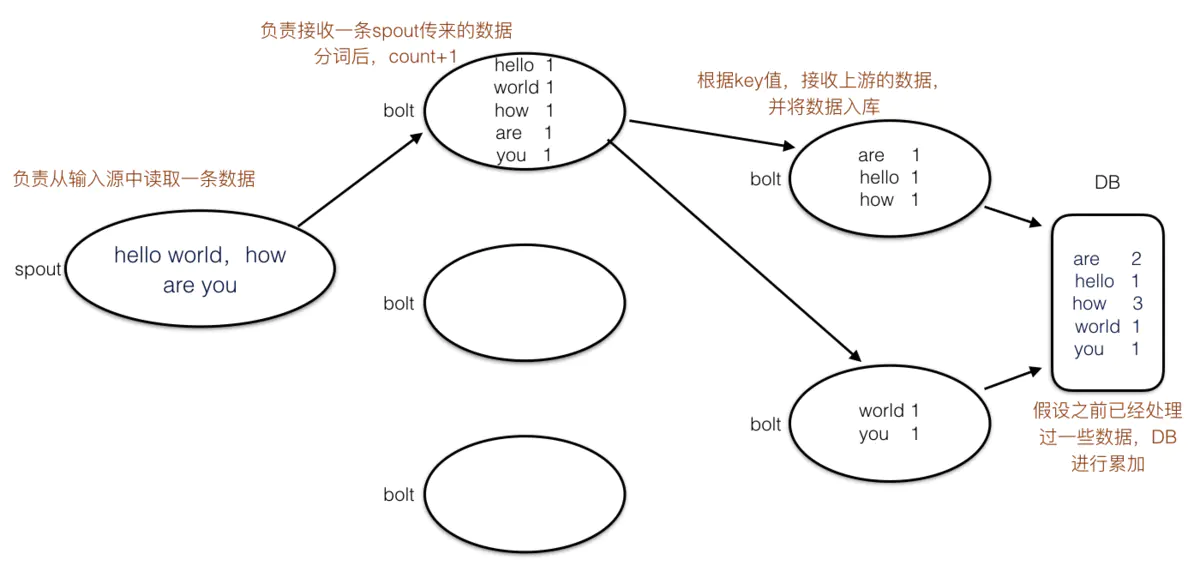
spout:负责从数据源接收数据
bolt:负责数据处理,最下游的bolt负责数据输出
spout不断从数据源接收数据,然后按一定规则发送给下游的bolt进行计算,最下游的bolt将最终结果输出到外部系统中(这里假设输出到DB),这样我们在DB中就可以看到最新的数据统计结果。Storm每一层的算子都可以配置多个,这样保证的水平扩展性。因为往往处理的是unbound data,所以storm中的算子都是长任务。
容灾
容灾是所有系统都需要考虑的一个问题,考虑一下:假如运行过程中,一个算子(bolt)因某种原因挂了,Storm如何恢复这个任务呢?
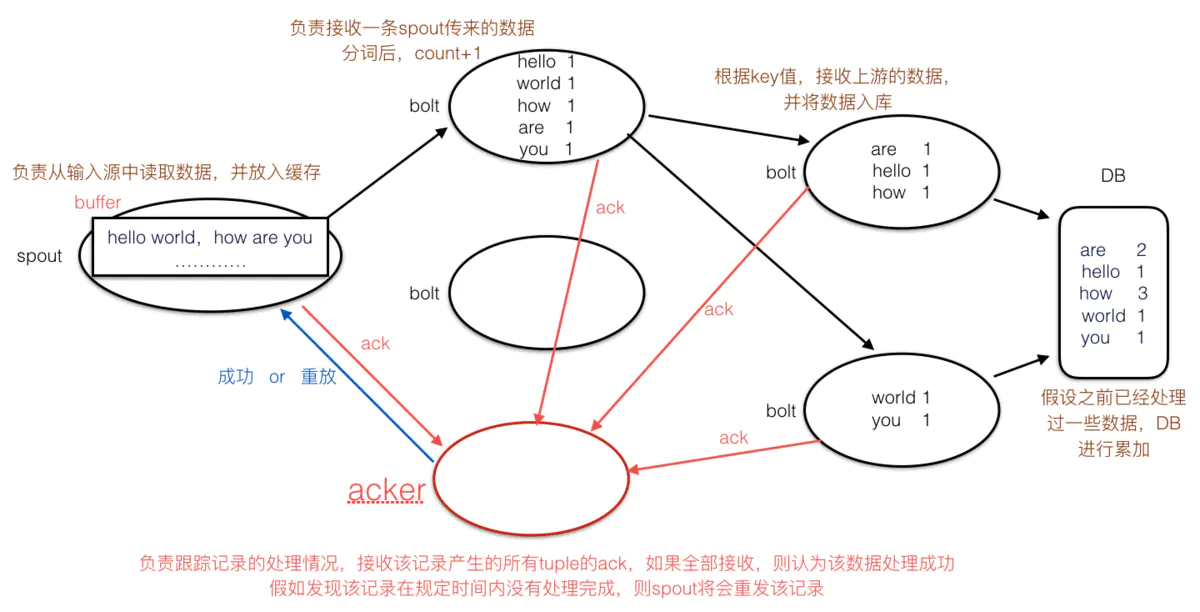
批处理解决方案就比较简单,拿MR举例,假如一个运行中map或reduce失败,那么任务重新提交一遍就ok(只不过重头计算又要花费大量时间),下面我们看看Storm是如何解决的:
storm的spout有一个buffer,会缓存接收到的record,并且Storm还有一个acker(可以认为是一个特殊的bolt任务),每条record和该record所产生的所有tuple在处理完成后都会向对应的acker发送ack消息,当acker接收到该record所有的ack消息之后,便认为该record处理成功,并通知spout从buffer中将该record移除,若receiver没有在规定的时间内接收到ack,acker则通知spout重放数据。
acker个数可以由用户指定,因为数据量比较大时,一个acker可能处理不过来所有的ack信息,成为系统瓶颈(如果可以容忍数据丢失,当然也可以关闭ack机制,可以显著提高系统性能)。并且acker采用了巧妙的机制,优化了ack机制的资源占用(有兴趣的同学可以参考官网,网上也有很多博客介绍ack具体实现)。
Storm采用ack机制实现了数据的重放,尽管做了很多优化,但是毕竟每条record和它产生的tuple都需要ack,对吞吐还是有较大的影响,关闭ack的话,对于某些不允许丢数据的业务来说又是不可接受的。
Storm的这种特点会导致大家认为:流式计算的吞吐不如批量计算。(这点其实是不对的,只能说Storm的设计导致了它的吞吐不如批量计算,一个设计优秀的流式系统是有可能拥有和批处理系统一样的吞吐)
数据不重不丢
之前我们提到早期的流式系统无法提供精准的计算服务,下面我们详细了解一下:
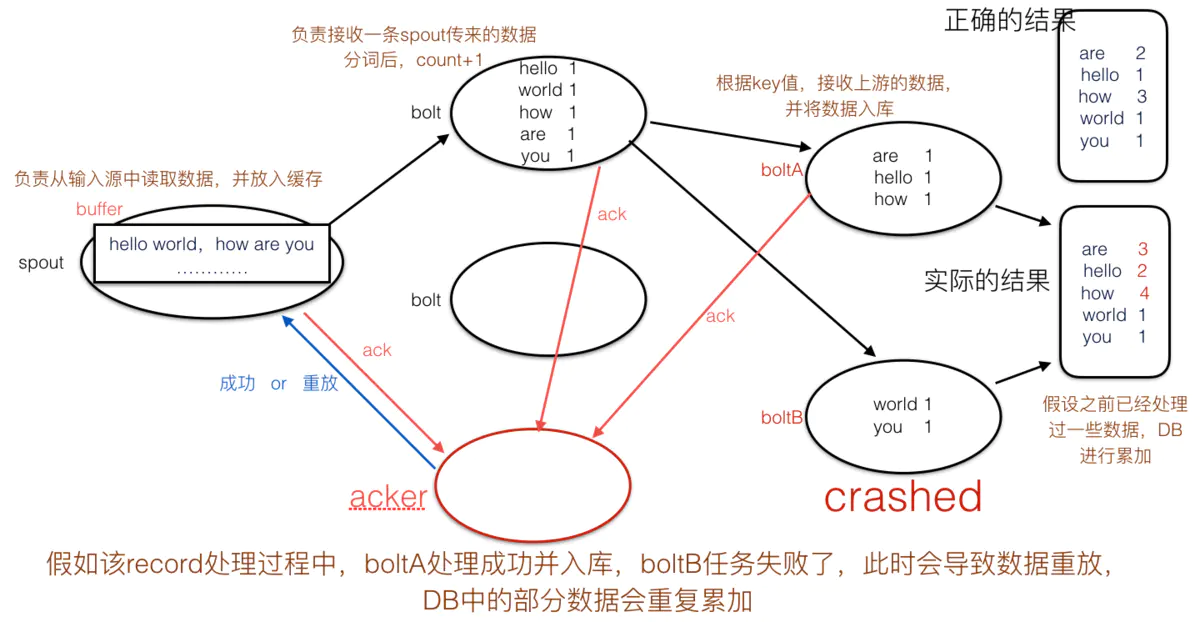
sink处的重复输出:假如运行过程中,boltA数据入库后,boltB因为某种原因crash了,这时候会导致该record重放,boltA中已经处理过的数据会再次入库,导致部分数据重复输出。
不仅sink处存在重复输出的问题,receiver处也同样存在这种问题。(在讲解Spark streaming处会详细介绍什么情况下receiver会重复接收数据)
Storm没有提供exactly once的功能,并且开启ack功能后又会严重影响吞吐,所以会给大家一种印象:流式系统只适合吞吐相对较小的、低延迟不精确的计算;而精确的计算则需要由批处理系统来完成,所以出现了Lambda架构,该架构由Storm的创始人提出,简单的理解就是同时运行两个系统:一个流式,一个批量,用批量计算的精确性来弥补流式计算的不足,但是这个架构存在一个问题就是需要同时维护两套系统,代价比较大。
那么有没有一种架构,可以满足高吞吐、低延迟的要求,同时也提供exactly once功能?有的,下面我们来看看Spark streaming。
Spark streaming
吞吐
Spark streaming采用小批量的方式,提高了吞吐性能:
这里我们简单展示Spark streaming的运行机制,主要是与Storm做下对比。Spark streaming批量读取数据源中的数据,然后把每个batch转化成内部的RDD。Spark streaming以batch为单位进行计算(默认1s产生一个batch),而不是以record为单位,大大减少了ack所需的开销,显著提高了吞吐。
但也因为处理数据的粒度变大,导致Spark streaming的数据延时不如Storm,Spark streaming是秒级返回结果(与设置的batch间隔有关),Storm则是毫秒级。
不重不丢(exactly once)
Spark streaming通过batch的方式提高了吞吐,但是同样存在上面所说的数据丢失和重复的问题。
在解答这个问题之前,我们先来了解一下一些概念:
1.at most once:最多消费一次,会存在数据丢失
2.at least once:最少消费一次,保证数据不丢,但是有可能重复消费
3.exactly once:精确一次,无论何种情况下,数据都只会消费一次,这是我们最希望看到的结果
大部分流式系统都提供了at most once和at least once功能,但不是所有系统都能提供exactly once。
我们先看看Spark streaming的at least once是如何实现的,Spark streaming的每个batch可以看做是一个Spark任务,receiver会先将数据写入WAL,保证receiver宕机时,从数据源获取的数据能够从日志中恢复(注意这里,早期的Spark streaming的receiver存在重复接收数据的情况),并且依赖RDD实现内部的exactly once(可以简单的理解采用批量计算的方式来实现)。RDD:Resilient Distributed Dataset弹性分布式数据集,Spark保存着RDD之间的依赖关系,保证RDD计算失败时,可以通过上游RDD进行重新计算(RDD如何实现容错这里就不解释了,可以自行查资料)。
上面简单解释了Spark streaming依赖源数据写WAL和自身RDD机制提供了容灾功能,保证at least once,但是依然无法保证exactly once,在回答这个问题前,我们再来看一下,什么情况Spark streaming的数据会重复计算。
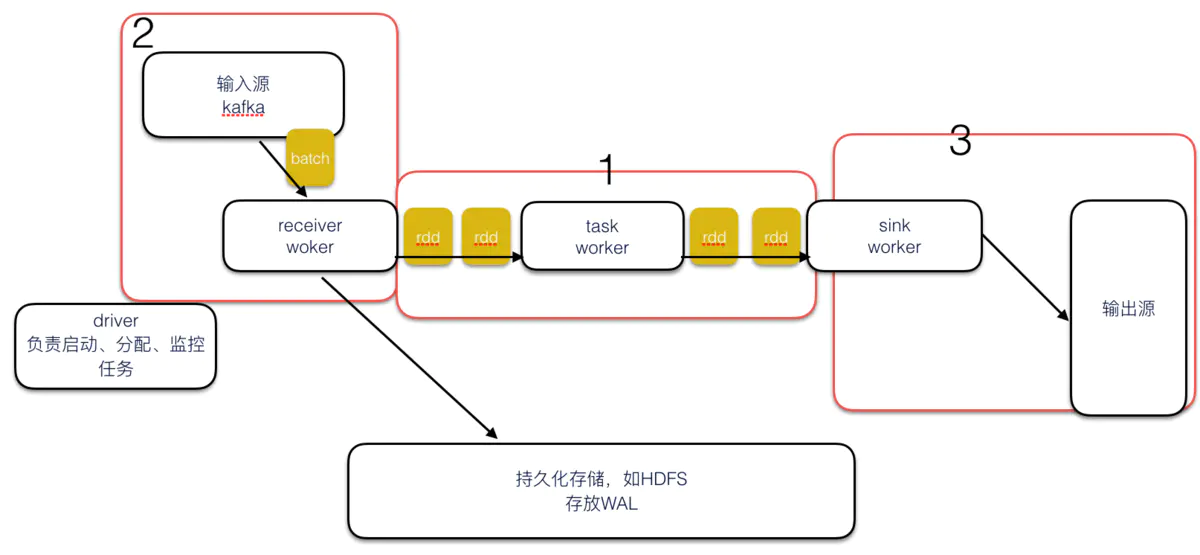
这里我们主要关注图中的3个红框:
Spark streaming的RDD机制只能保证内部计算exactly once(图中的1),但这是不够的,回想一下刚才Storm的例子,假如某个batch中,sink处一部分数据已经入库,这时候某个sink节点宕机,导致该节点处理的数据重复输出(图中的3,Storm处已经解释过了)。还有另一种情况就是receiver处重复接收数据(图中的2),我们看一下receiver重复接收数据的情况:
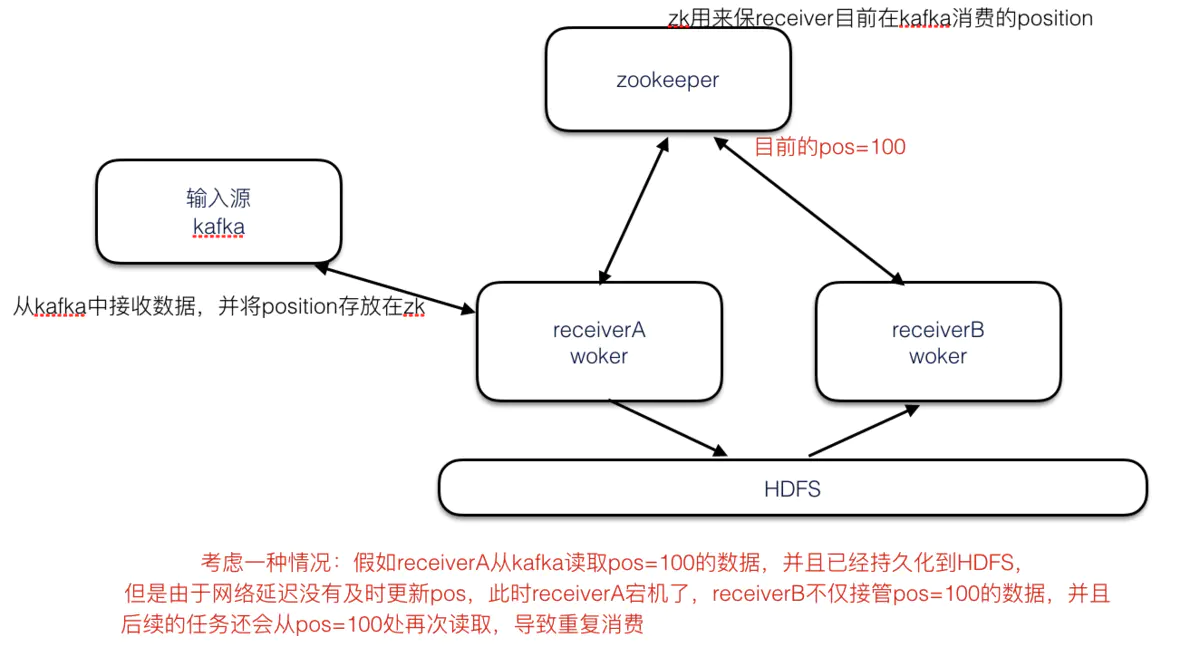
假如receiverA目前从kafka读到pos=100的记录,并且已经持久化到HDFS,但是由于网络延迟没有及时更新pos,此时receiverA宕机了,receiverB接管A的数据,并且后续的任务还会从pos=100处重新读取,导致重复消费。造成这种情况的主要原因就是:receiver处数据消费和Kafka中position的更新没有做到原子性。
根据上面的讨论,可以得出:一个流式系统如果要做到exactly once,必须满足3点:
1.receiver处保证exactly once
2.流式系统自身保证exactly once
3.sink处保证exactly once
这里数据源采用Kafka举例是因为Kafka作为目前主流的分布式消息队列,比较有代表性。Kafka consumer的position可以保存在ZK或者Kafka中,也可以由consumer自己来保存。前者的话就可能存在数据消费和position更新不一致的问题(因为无法保证原子性,也是之前Spark streaming采用的方式),而采用后者的话,consumer可以采用事务更新的方式(写本地或者采用事务的方式写数据库),保证数据消费和position更新的原子性,从而实现exactly once(参考)。
Spark streaming 实现 exactly once
Spark streaming1.3版本新添加了Kafka Direct API来实现数据接收的exactly once,本质上就是上面提到的后者,Spark streaming自己维护position,streaming的worker直接从Kafka读取数据,position由Spark streaming管理,不再依赖ZK保存,同时保证数据消费和更新position的原子性,从而实现exactly once。
并且新的方式已经不再需要receiver持久化数据,因为Kafka本身就支持数据持久化,可以避免receiver处持久化数据的开销,实现exactly once的同时也提高了性能。
而sink处的exactly once的实现则视外部系统而定,比如文件系统本身就支持幂等(同一个操作执行多次,不会改变之前的结果),同时Spark streaming也提供了api,用户可以自己实现sink处的事务更新,receiver、sink和Spark streaming三者结合起来才能实现了真正的exactly once。
Storm trident本质上也是采用了小批量的方式,并且也实现了exactly once语义,这里就不做过多讨论。
直到这里,我们了解到Spark streaming拥有较好的吞吐和exactly once语义,解决了Storm一些不足,是不是只有采用类似Spark streaming这种小批量(micro-batch)的方式才能实现这些功能?答案是:NO。下面我们来看看Flink。
Flink
Flink在数据处理的方式上和Storm类似,并没有采用小批量,是一个真正的流式系统。它不仅拥有了不弱于Spark streaming的吞吐,并且提供了exactly once语义。既然Flink也是逐条处理记录,那么它是怎么做到的呢?跟上我的脚步...(下面内容大部分参考官网,捡重点的翻译,想起来一个段子:如何快速成为业界大牛?答:翻译英文文档。。hahaha,开个玩笑^ ^)
简单来说,Flink采用轻量级分布式快照实现容错,大致流程是:Flink不断的对整个系统做snapshot,snapshot数据可以放在master上或外部系统(如HDFS),假如发生故障时,Flink停止整个数据流,并选出最近完成的snapshot,将整个数据流恢复到该snapshot那个时间点,snapshot本身比较轻量,而且用户可以自行配置snapshot的间隔,snapshot的性能开销对系统的影响很小(官方测试snapshot开启前后的性能差距不大)。
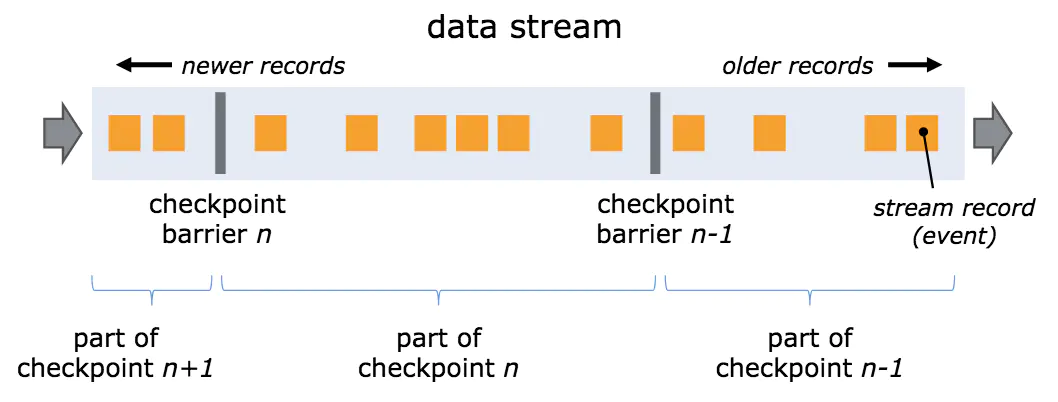
barrier是分布式snapshot实现中一个非常核心的元素,barrier和records一起在流式系统中传输,barrier是当前snapshot和下一个snapshot的分界点,它携带了当前snapshot的id,假设目前在做snapshot N,算子在发送barrier N之前,都会对当前的状态做checkpoint(checkpoint数据可以保存在外部系统中,如HDFS),checkpoint只包含了barrier N之前的数据状态,不会涉及barrier N之后的数据。
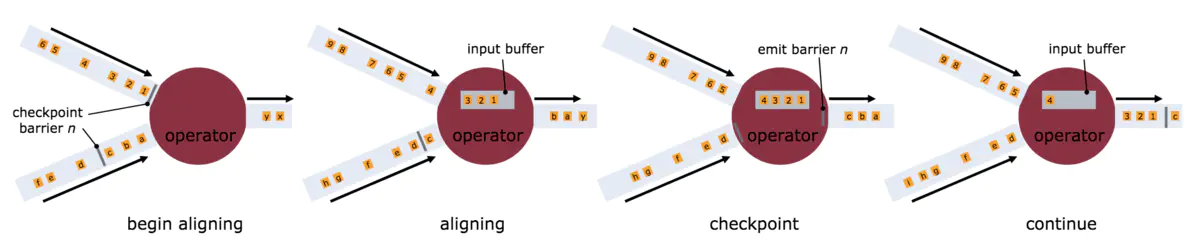
因为算子很多情况下需要接收多个算子的数据(shuffle操作),所以只有当所有上游的发送的barrier N都到达之后,算子才会将barrier N发送给下游(所有的下游)。当所有的sink算子都接收到barrier N之后,才会认为该snapshot N成功完成。
为了保证一致性,需要遵守以下几个原则:
1.一旦算子接收到某一个上游算子的barrier之后,它不能再处理该上游后面的数据,只有当它所有上游算子的barrier都到达,并将barrier发送给下游之后,才能继续处理数据,否则的话会造成snapshot N和N+1的数据重叠。
2.某个上游算子的barrier到达之后,该上游算子后续的数据将会被缓存在input buffer中。
3.一旦所有上游的算子的barrier都到达之后,该算子将数据和barrier发送给下游。
4.发送成功之后,该算子继续处理input buffer中的数据,并继续接收处理上游算子发送过来的数据。(有点啰嗦啊)
下面我们来看一个完整的snapshot流程图:
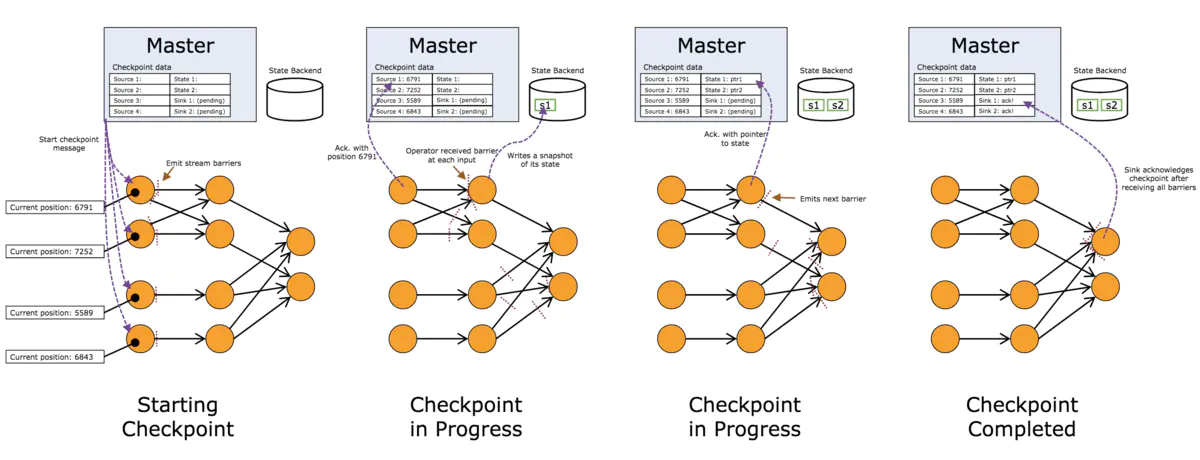
图片有点不清晰,可以自己去官网看,笔者比较蠢,怎么都截不下来高清的
图中的Master保存了snapshot的状态,假设数据还是从Kafka中获取,首先receiver算子会先将当前的position发送给master,记录在snapshot中,并同时向下游发送barrier,下游的算子接收到barrier后,发起checkpoint操作,将当前的状态记录在外部系统中,并更新Master中snapshot状态,最后当所有的sink算子都接收到barrier之后,更新snapshot中的状态,此时认为该snapshot完成。
通过这种轻量级的分布式snapshot方式,Flink实现了exactly once,同时Flink也支持at least once,也就是算子不阻塞barrier已经到达的上游算子的数据(多个上游算子的情况),这样可以降低延迟,但是不保证exactly once。
从图中我们可以看出Kafka position也是由Flink自己维护的,所以能够保证receiver处的exactly once,sink处也同样存在Spark streaming一样的问题,exactly once依赖外部系统或需要用户自己实现。Flink官网给出了目前支持的Data Sources和Sinks以及容错的粒度。
其中sink处采用Kafka的话不支持exactly once,个人猜想是不是因为早期的Kafka producer没有支持exactly once语义,而导致Flink无法支持。Kafka0.11版本中添加了producer exactly once的支持,是否后续能够添加进来?
讲到这里,我们可以了解到:
1.流式系统并不一定就是吞吐差的代名词
2.流式系统也可以做到exactly once
就如Google流式系统负责人Tyler Akidau所说:一个设计良好的流式系统是能够在吞吐完全媲美批量系统,并且提供精准的实时服务。(那是不是以后可以完全用流式系统取代批量系统?)
window和event time
Flink相比Spark streaming不仅提供了更低的延迟,而且Flink还对window和event time提供了更好的支持。window和event time又是什么呢?
window
现实生活中,大部分数据源其实是unbound data,没有边界,我们没有办法得到一个最终的统计结果,很多情况下我们会对固定时间间隔的数据进行统计,比如每5s统计一下服务器的qps,window机制能够帮我们很好的完成这项需求。
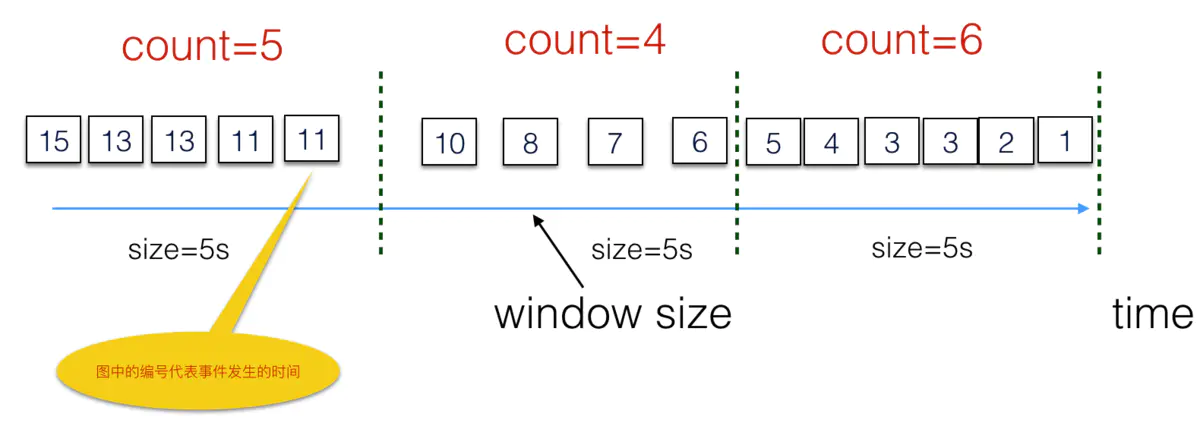
如图(标号代表事件发生的时间),流式系统会每隔5s创建一个window,将该时间段的数据放入buffer,累加后输出结果。图中0-5s产生的数据放在第一个window中(3s处有两条数据),累加后输出count=6。
window类型也有很多种,上图是一个Tumbling Windows的例子,另外还有Sliding Windows和session window,具体区别读者可以自行查资料。
上图是一个比较理想的示例图,理想很丰满,现实很骨感,事情往往不尽如人意(情不自禁的都想唱起来了:人生已经如此的艰难,有些事情就不要ao......流式系统的破事怎么这么多!!),直接按接收时间来划分window可能会存在误差:
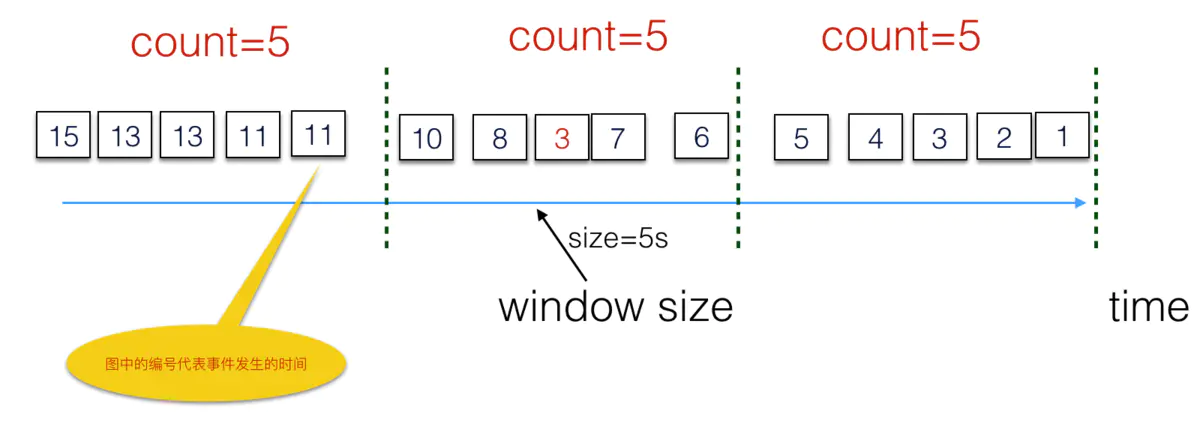
假设由于网络延迟,应该属于第一个窗口的数据3延迟到达,被分到了第二个窗口,这时候计算结果并不准确。怎么办呢?
event time和process time:
假设一个流式系统目前正在接收并处理用户手机的日志,但是由于网络延迟,或者用户手机离线,导致日志没有及时发送到流式系统,流式系统观察到数据的时间和数据真正产生的时间可能存在偏差,我们把数据真正产生的时间叫做:event time,把流式系统处理该数据的时间叫做:process time。
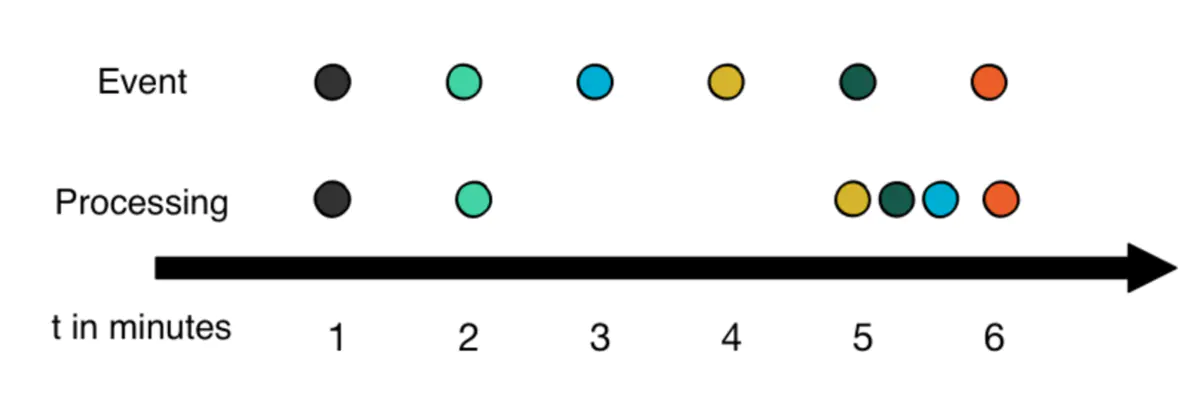
event time和process time往往会存在延迟,这种不一致会导致数据乱序,如图所示:蓝色事件晚于黄色事件发生,但是事件的处理却先于黄色事件。
早期的流式系统并没有区分process time和event time,往往将process time等同于event time。针对这一问题,一个很直观的解决方案就是:让数据自身携带timestamp,该timestamp记录该数据产生的时间,即为event time,流式系统按数据的event time来将数据分配到对应的窗口,而不是按处理数据的时间。
window需要知道该窗口的数据都已经全部到达,然后触发计算逻辑,如何window判断时间T之前的数据是否都已经到达呢?
watermark
那就是引入watermark机制,watermark同样也携带一个时间戳,当算子接收到watermark T后,就代表时间T之前的数据已经接收完毕,不会再有小于时间T的数据。

如图:W(17)到达后,表示后续数据的时间戳不会小于17。那可能有人会问了:那就是有一部分小于17的数据他喵的就是比w(17)还晚到了怎么办?
watermark还会配合一个allow lateness参数,window接收到watermark后,再等待一段时间才会关闭窗口,如果这段时间有些数据依然没有发送过来,那就只能忽略它们了(window的内心os:我也尝试过等待,但我还有更重要的事情要做),而且考虑到流式系统的实时性,假如可接受的时间内,数据没有传输过来,那就算等到它过来再计算,从实时性这个角度来说,这时计算的结果也有可能也已经没有意义了。
Flink对window和watermark都提供了较好的支持,Spark streaming从2.0中也开始引入watermark功能,但是支持的功能有限,并且真正的流式可以更优雅、简单的实现window和watermark,从这个角度来看,Flink是优于Spark streaming的。
总结:
了解了Storm、Spark streaming、Flink各自的特点后,我们知道Storm提供了低延迟的计算,但是吞吐较低,并且无法保证exactly once(Storm trident采用batch的方式改善了这两点),Spark streaming通过小批量的方式保证了吞吐的情况下,同时提供了exactly once语义,但是实时性不如Storm,而且由于采用micro-batch的方式,对window和event time的支持比较有限(Spark streaming2.0中引入了window和event time,还在起步阶段)。Flink采用分布式快照的方式实现了一个高吞吐、低延迟、支持exactly once的流式系统,流式处理的方式也能更优雅的支持window和event time。
当然也不是说Flink一定就比Storm、Spark streaming好,没有最好的框架,只有最合适的框架,根据自身的业务、公司的技术储备选择最合适的框架才是正确的选择。
end
https://www.jianshu.com/p/16323566f3c6
作者:奔跑的番茄酱
链接:https://www.jianshu.com/p/16323566f3c6
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
